

Release 1.4.0. September 2024
1 Key Concepts
1.1 Online Controlled Experiments
In an online controlled experiment, a modification to the existing user experience co-exists, for a time, with the original experience. User traffic is split randomly between the two experiences, and measurements are collected of some target metric, e.g. rate of conversion to the next page. In scientific terms, the existing experience serves as control and the new experience as treatment. The experiment is said to succeed if it reaches statistical significance — a mathematical term connoting that a) the number of measurements taken is large enough, and 2) the observed difference between the metric’s values in control and in treatment is large enough, to conclude that this difference is far more likely due to the difference between the two experiences, than to mere chance.
For example, you may want to run an experiment to find out the optimal minimum order amount you can ask in return for free shipping. In such an experiment you offer several experiences, each requring a different minimum order amount and target your user traffic to these experiences randomly. As your customers pass through these experiences you can compare the offer take rate and your revenue lift between the treatments.
Note, that in the case of online controlled experiment, in order to interpret correlation as causation, session targeting must be random, because randomness serves a natural control for everything other than the difference in user experience itself.
1.2 Feature Gates
Feature gates, sometimes also called feature roll-outs, are a software delivery practice, where a new product feature is rolled out gradually to a carefully controlled group of customers before it is made generally available. Whenever you roll out a new product feature, a feature gate enables you to first publish it to a limited population of users, gradually increasing traffic into the new code path.
Variant treats feature gates as a special case of controlled experiments with the following constraints:
- Feature gates can only have one experience, which is automatically assumed to be control.
- Because feature gates are not intended to be analyzed, Variant by default does not log any trace events for them.
- Traffic into a feature gate is controlled by qualification. All qualified traffic is automatically targeted for the sole control experience.
Throughout Variant documentation, feature gates are referred to as simply gates.
1.3 Interactive Application as a Graph
The only assumption Variant makes about the host application is that it is interactive, i.e. pauses for and responds to user input. Its control flow is commonly represented with traversal graphs, like in Figure 1 below. Here the nodes represent the interface states where the system awaits user input and the arcs represent the application responding to user input. Interpreted as a state machine, each node is also a state of the application.
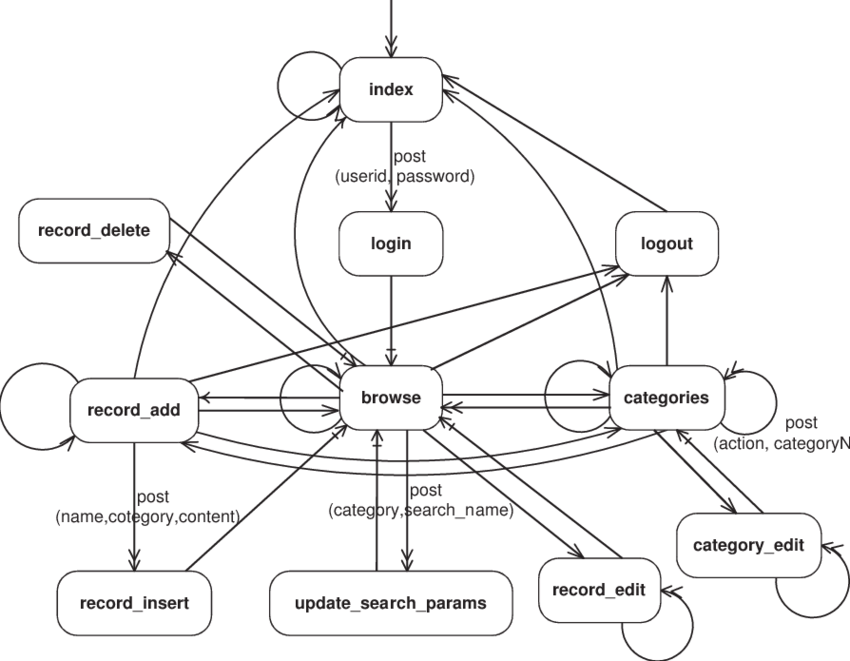
Figure 1. An interactive application modeled as a state graph. (Source: Offutt et al, 2004)
Irrespective of the actual user interface mechanism, application states render some user interface and provide the means for the user to respond. Depending on the type of the host application, this interface may be manifested as a computer desktop window, an Web page, a mobile screen, a phone menu, etc.—these details are not relevant to Variant.
A traversal of a set of interface states, as user transitions from one Web page or one telephone menu to the next is what constitutes a user experience, which can be more strictly defined as some connected segment of the application state graph.
Normally, each application state exists in a single variant. (There’s only one checkout page.) To model alternate code paths, Variant distinguishes between a base state and zero or more of its state variants. At runtime, the host application chooses which state variant to traverse. These alternate code paths is what we call state variants. The control user experience is the one that traverses the base states, while a variant user experience is one that traverses variant states.
Whenever the host application receives user input, it navigates to the next interface state. If the target interface state exists in more than one variant, the host application must pick a viriant to present to the user, Figure 2 below:
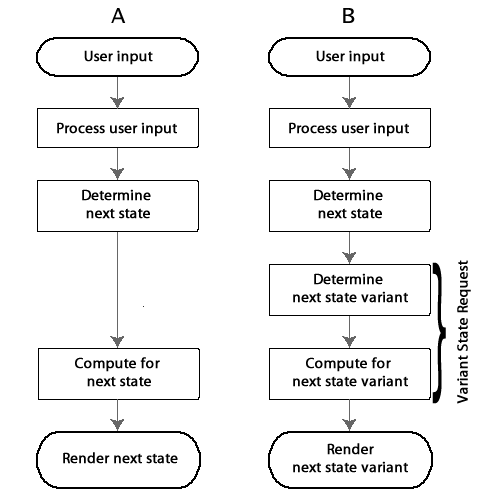
Figure 2. A state transition without state variant (A); and with state variants (B).
In the regular, uninstrumented case (A), the application simply figures out the next state based on the user’s input, carries out requisite computations, renders the state’s interface to the user, and pauses for user input. However, if the next state is instrumented by one or more experiments (B), the host application must pick one of them.
It is exactly this task of figuring out the particular state variant that the host application delegates to Variant server, just like it delegates to a database server the task of managing persistent data.
The part in the state transition where the host application defers to Variant for targeting is called a state request. A Variant session is, in the nutshell, a succession of state requests plus the common session state, preserved by Variant server between the state requests.
1.4 Variant Domain Model
Variant domain model offers a framework for formal definitions of experiments (both online controlled experiments and gates) and for reasoning about them. Its key practical benefit is that it provides a way to externalize the metadata for a set of related experiments into human readable schema files managed centrally by Variant server. These schemas enable developers to define experiments declaratively, rather than programmatically, leaving the details to be handled by the Variant server.
This removes oodles of instrumentation code from the host application. The application developer uses familiar tools to implement new application behaviors, unconcerned with how these new code paths will be instrumented as experiments or gates. This instrumentation is accomplished with only a few lines of glue code facilitating the communication between the host application and the Variant server. The experiment schemas containing the definitions of all experiments are managed entirely by the Variant server, removing enormous amounts of experiment instrumentation complexity from the host application’s code base.
This clean separation between implementation and instrumentation dramatically reduces the amount of code the application developer must write in order to instrument new application code paths as experiments. In fact, it takes the same number of lines of code (about a dozen) to instrument your 100th concurrent experiment as it takes you to instrument your first.
In other words, Variant brings down the human-effort complexity of instrumenting N concurrent experiments to be linear in the number of experiments.
1.5 Simple Experiment Schema
A minimal valid experiment schema consists of a single state, instrumented by a gate — an experiment with a sole experience:
# A very simple experiment schema take 1.
name: MinialSchema
states:
- name: passwordResetPage
experiments:
- name: recaptcha
experiences:
- name: withRecaptcha # Single experience defaults to control.
onStates:
- state: passwordResetPageListing 1. A minimal valid experiment schema with a gate around the new code path adding reCAPTCHA to the existing password reset page.
To deploy this schema, simply copy the file to the server’s schemata directory. Although it deploys without error, it does not do anything useful yet because it is missing a custom qualification hook. In the absence of such a hook, the default qualification hook qualifies all traffic into the gate, defeating its very purpose. To make this gate useful, we add a custom qualification hook, which will qualify into this experiment only certain users based on their IDs:
package mycompany.variant.spi;
import com.variant.server.spi.QualificationLifecycleEvent;
import com.variant.server.spi.QualificationLifecycleHook;
import com.variant.share.yaml.YamlList;
import com.variant.share.yaml.YamlNode;
import com.variant.share.yaml.YamlScalar;
import java.util.Arrays;
import java.util.Optional;
/**
* Custom qualification hook qualifies user IDs provided at initialization.
*/
public class RecaptchaQualificationHook implements QualificationLifecycleHook {
private final String[] qualifiedUserIds;
public RecaptchaQualificationHook(YamlNode<?> init) {
qualifiedUserIds =
((YamlList)init).value().stream()
.map(node -> ((YamlScalar<String>)node).value())
.toArray(String[]::new);
}
@Override
public Optional<Boolean> post(QualificationLifecycleEvent event) {
Boolean isQualified = event.getSession().getOwnerId()
.map(userId -> Arrays.stream(qualifiedUserIds).anyMatch(userId::equals))
.orElse(false);
return Optional.of(isQualified);
}
}Listing 2. Custom qualification hook qualifies into an experiment only those users whose IDs are passed to its constructor.
To add this hook to the experiment use the schema hooks key:
# A very simple experiment schema take 2.
name: MinimalSchema
states:
- name: passwordResetPage
experiments:
- name: recaptcha
experiences:
- name: recaptcha
onStates:
- state: passwordResetPage
hooks:
- class: mycompany.variant.spi.RecaptchaQualificationHook
init: [USERID1 USERID2 USERID3]Listing 3. The minimal valid experiment schema that does something useful.
Now, whenever the Variant server needs to qualify a session for the recaptcha gate, it will delegate to the RecapthaQualificationHook hook which will only qualify into the feature those user sessions whose user IDs match those provided in the init list.
2 Session Qualification and Targeting
2.1 Qualification vs. Targeting
Variant’s domain model clearly distinguishes between qualification and targeting. For example, you may want to run an experiment to find out the optimal minimum order amount you can ask in return for free shipping. In such an experiment you offer several experiences, each requiring a different minimum order amount and target your user traffic to these experiences randomly. As your customers pass through these experiences you can compare the offer take rate and your revenue lift between the treatments and the control.
Suppose now that you do not wish to combine the offer of free shipping with some other promotion. Clearly, this constraint is a matter of qualification, and not targeting. Users already in another promotion should be disqualified from the free shipping experiment—not merely targeted to the control experience. Rather, Variant server assigns disqualified sessions to the control experience triggering no trace events as it passes through the experiment for which it is not qualified.
Before any actual targeting can take place, a user session must first be qualified. Only qualified sessions will be targeted to an experience through some randomized mechanism. A qualified session may also end up being targeted to the control experience, but this time Variant server will trigger state visited events for it, in contrast to the disqualified case.
2.2 Time-to-Live (TTL)
When a user session is first qualified or targeted for an experiment, schema designer has the choice of the effective lifespan of these decisions. For example, it is typically desirable that a user continues to see the same UI on return visits, for example to ensure that returning users continue through a multi-page wizard without the risk of inconsistencies if they switch to a different device.
Variant allows experiment designer to choose between three progressively more durable time-to-live (TTL) settings: state, session and experiment. An experiment’s qualification and targeting TTLs are specified in the experiment schema independently. For example, a user’s eligibility for an experiment, e.g. related to a promotion, may vary from visit to visit. But whenever a user is qualified, the experiment designer typically wants her to see the same experience for the duration of the experiment.
More formally:
- State scoped TTL means that the outcome of qualification or targeting is not reused. An experiment with state-scoped qualification is re-qualified for each state request, and an experiment with state-scoped targeting, if qualified, is re-targeted for each state request.
- Session scoped TTL means that the outcome of qualification or targeting is reused for the duration of current user session. An experiment with session-scoped qualification is qualified once per session and the qualification decision is reused for the remainder of this session. The same user’s other session will be re-qualified. An experiment with session-scoped targeting is targeted once per session and the targeting decision is reused for the remainder of this session. The same user’s other session will be re-targeted, if qualified.
- Experiment scoped TTL means that the outcome of qualification or targeting is reused for the entire lifespan of the experiment—effectively forever. An experiment with experiment-scoped qualification will be qualified once, and the qualification decision will be reused for as long as this experiment is defined in the schema. An experiment with experiment-scoped targeting will be targeted once, and the targeting decision will be reused for as long as the experiment is defined in the schema.
To illustrate the difference between these TTLs, consider the following use cases.
- Suppose you want to test a new signup funnel experience which is expected to improve conversion. Clearly, you want to only qualify those visitors who have not yet signed up. As soon as they do signup, even in the course of the current session, you don’t want them to continue seeing the experiment experience. This is accomplished with state-scoped qualification.
- Session-scoped targeting are useful in experiments where there’s no difference in the user experience between control and variants, such as optimization of internal algorithms like search or associations. By using session-scoped targeting the experiment designer effectively uses each user’s visit as an independent trial, taking full advantage of the traffic.
- Experiment-scoped targeting is a common strategy for those experiments, where it is desirable that the return users see the same experience. Most experiments that involve changes to the user experience require this guarantee. For example, if you want to experiment making improvements to an online loan application, your user must be able to break for lunch in the middle of the process and come back to the same experience she had before.
2.3 Experiment-Scoped TTL
Variant server can handle state and session-scoped TTLs even if the user is anonymous. However, experiment-scoped targeting or qualification require Variant server to store them in an embedded database to be reused on the user’s next visit. This necessitates that the application programmer provide a unique session owner ID, which Variant server uses as the database key. The host application sets the session owner by passing the ownerId to the Connection.getOrCreateSession() method:
User appUser = ... // Represents the host application's User object
Session ssn = variantConnection.getOrCreateSession(userData, Optional.of(appUser.userId));Variant guarantees session-scoped qualification and targeting to be unconditionally stable, because Variant sessions are isolated from any schema changes, as explained in section 6.3 Schema Management. However, experiment-scoped TTL cannot be guaranteed unconditionally, because experiment schema may change between two consecutive session. Consider the following scenario:
- Your schema contains two explicitly concurrent experiments, both defined with experiment-scoped targeting time-to-live.
- Some user has traversed these experiments and was randomly targeted to variant experiences in both;
- A bug was discovered in the hybrid experience and you’ve changed concurrency to implicit in order to avoid the hybrid experience for a time.
- The same user visits again. Her targeting information is no longer consistent with the schema and must be revised.
When cases like this arise, Variant will discard the least recently used targeting decision and re-target.
3 Concurrent Experiments
3.1 Definitions
If two experiments instrument no states in common, they are called serial experiments; a user session can only traverse them one at a time. Conversely, whenever two experiments instrument one or more states in common, they are called concurrent experiments because a user session may be traversing them at the same time. (The term “overlapping experiments” is also commonly used.)
Concurrent experiments are more likely than it may first seem, because of the Pareto principle; 80% of a typical interactive application’s traffic goes to 20% of its interface states. These higher-contention code paths are very likely to be instrumented by multiple concurrent experiments and gates. Variant’s domain model gives you a cogent abstraction to manage this concurrency.
In Figure 3 below, Blue and Green experiments are serial, but Red experiment is concurrent with both of them.
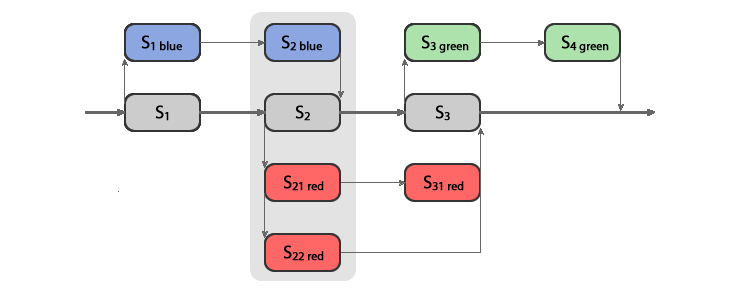
Figure 3. Concurrent experiments. Blue and Green experiments are serial, while Red is concurrent with both Blue and Green. The grey boxes denote control states, while the colored ones denote state variants.
When a user session targets a state that is instrumented by two or more experiences, Variant server creates a state variant space of possible experience permutations from which any combination of state variants potentially can be chosen. For example, the state S2 is instrumented by Blue and Red experiments. Blue only has one variant experience and Red has two variant experiences, so the complete variant space of the state S2 has 6 cells:
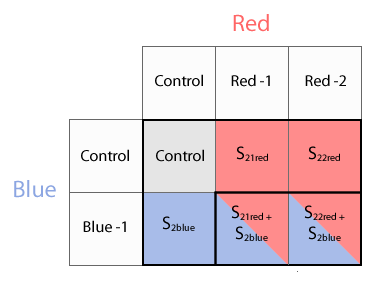
Figure 4. Variant space of the state S2 has one control, three proper, and two hybrid state variants.
The relationship of concurrence between two experiments E1 and E2 has the following properties:
- Symmetric: If expeirment
E1is concurrent with experimentE2, thenE2is concurrent withE1. The experiment schema grammar takes advantage of this by requiring the concurrency relationship to be defined by the experiment that appears in the schema after the referenced experiment. - Not Reflexive: an experiment is not concurrent with itself.
- Not Transitive: If
E1is concurrent withE2andE2is concurrent withE3, thenE1andE3need not be concurrent.
3.2. Implicit Concurrency
If two concurrent experiments are defined in the experiment schema independently, they are called implicitly concurrent. In this case, Variant cannot target a session in both experiments independently, because of the possibility that the session would be targeted to a hybrid experience, which Variant has no reason to assume exists. Variant implements this safety property in the default qualifier hook, which disqualifies a session for any experiment implicitly concurrent with an already targeted live experiment.
This default makes sense: application developers should not have to coordinate with each other simply because they work on potentially overlapping features. Moreover, sometimes two concurrent experiments are mutually exclusive and no user should ever qualify for both. However, the price for this convenient safe default is the potential starvation of downstream experiments of user traffic. This can be mitigated by two mechanisms:
- A custom qualification hook can artificially (and randomly!) disqualify users for the upstream experiments to free up more traffic for the downstream ones.
- Implement the hybrid experiences and explicitly declare the two experiments as concurrent, as explained in the next section.
3.3 Explicit Concurrency
Assuming two concurrent experiments are not mutually exclusive, the experiment designer may prefer to instrument concurrent experiments to be targeted independently, in order to increase traffic into them. First, the application developer must implement all hybrid experiences. Then, use the concurrentWith schema key to tell Variant server that the two concurrent experiences can be treated as such.
The listing 4 below is the complete experiment schema for Blue, Red and Green experiments from the Figure 3 above. To illustrate both concurrency modes, Red and Blue experiments are defined as concurrent but not Green and Red experiments.
name: TricolorSchema
description: Demonstratges instrumentation of concurrent experiments on Figure 3
states:
- name: S1
- name: S2
- name: S3
- name: S4
experiments:
- name: Blue
experiences:
- name: grey
isControl: true
- name: blue
onStates:
- state: S1
- state: S2
- name: Red
# Red is explicitly concurrent with Blue.
concurrentWith: [Blue]
experiences:
- name: grey
isControl: true
- name: red_1
- name: red_2
onStates:
- state: S2
- state: S3
- name: Green
# Green is serial with Blue and implicitly concurrent with Red
experiences:
- name: grey
isControl: true
- name: green
onStates:
- state: S3
- state: S4
# S4 does not exist in control.
experiences: [green]Listing 4. The Tricolor experience schema of concurrent experiments from Figure 3. Red and Blue experiments are explicitly concurrent, which signals Variant server that the application developers took the trouble to implement hybrid experiences illustrated in figure 4.
Note as well the experiences key for the Green experiment on state S4 (line 38). It is needed in order to alert Variant that the control experience grey is not defined on S4.
4 Variant Platform Architecture
4.1 Overview
Variant server is deployed on the network local to the host application and its operational database either on premises or on the customer’s own compute instance in the cloud. (A fully managed Variant Platform-as-a-Service is under development.) Being on the same local network facilitates reliable real-time integration with the operational data for the purposes of qualification, targeting, and trace event egestion.
The following diagram presents a high-level overview of the different components of Variant software platform:
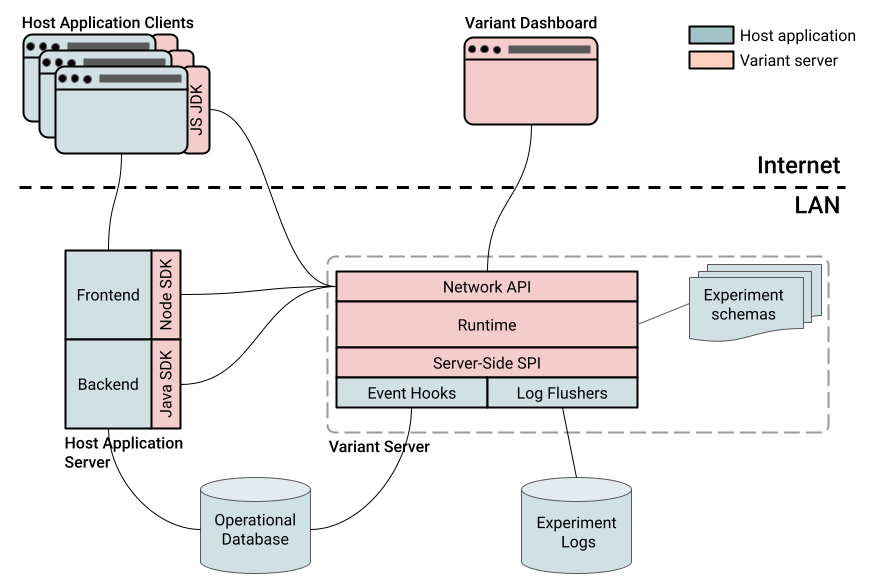
Figure 5. Variant Platform Architecture.
4.2 Client-Facing Network API
Each component of the host application that wishes to participate in an experiment or a gate communicates with Variant server via a native client SDK. Typically, only one instance of the Variant API handle is necessary per process, and only one connection is necessary per experiment schema. If you need to connect to multiple schemas, each schema requires a separate connection handle.
At the time of this writing only the Variant Java Client library is available.
4.3. Server-side Extension SPI
Variant server’s functionality can be extended through the use of the server-side extension service programming interface (SPI), which enables user-defined code to be directly executed by the server process. The server-side SPI exposes Java bindings which facilitate injection of custom semantics into the server’s default execution path via an event subscription mechanism. Two types of user-defined event handlers are supported:
- Lifecycle Hooks are handlers for various lifecycle events, such as when a session is about to be qualified for an experiment. A user-defined handler can implement a custom qualification logic, e.g. checking if the user is already registered, when a gate is only open to unregistered users.
- Trace Event Flushers handle the egest of trace events into external storage, like a database or an event queue. Each experiment schema can define its own event flusher.
Refer to the Server-Side Extension SPI User Guide for more information.
4.4 The Lifecycle of an Experiment
The other responsibility of the Variant server is the management of experiment lifecycle — the creation, alteration, and deletion, of experiments and gates. These actions are triggered by changes to experiment schema files residing on the server’s /schemata directory. Each schema file is a YAML file, containing definitions of related experiments. A schema is first deployed to the Variant server when its YAML file is placed into the /schemata directory. A schema is undeployed from the Variant server when its YAML file is removed from the /schemata directory. Whenever a schema file is modified in place in the /schemata directory, the Variant server detects the change and attempts to redeploy the schema.
A single Variant server instance can manage an unlimited number of experiment schemas.
4.5 Distributed Session Management
Variant maintains its own user sessions, instead of relying on those, maintained by the host application, e.g HTTP sessions. Variant user sessions are distributed; changes made to a user session by one Variant client are available to all concurrent Variant clients. This architecture is particularly attractive to modern distributed applications made up of multiple service components. Any such component, connected to a Variant server, can get a hold of a user session by its session ID and obtain its current shared state.
Variant does not guarantee an automatically consistent view of the session’s shared state to all concurrent clients; a change made by one client is not automatically visible to others. Attempting to provide such a strong guarantee would be too expensive while still susceptible to race conditions. Instead, Variant client SDKs provide a way for the application programmer to explicitly synchronize the state when required.
4.6 Advantages of the Variant Architecture
More generally, Variant’s architecture provides the following benefits:
- Separation of implementation from instrumentation. New product features are implemented by application developers, their instrumentation as experiments and gates is handled by Variant, leading to linear human effort complexity.
- Separation of devops lifecycles. Experimentation and feature gating metadata is source controlled in their own artifacts, independently of the host application. This makes it easy to make trackable changes to experiments and gates external to the host application’s code base.
- Separation of workloads and provisioning. The runtime workload associated with experiments and gates is handled by the Variant server completely out of band of the host application. The Variant server runs on separately provisioned compute and network resources, leaving the host application’s resources unaffected by fluctuations in experimentation workload.
- Isolation from metadata changes. Whenever an experiment schema is redeployed, Variant server makes sure that the change is hidden from the in-progress user sessions. Only new sessions see the current experiment metadata.
5 Experiment Schema Reference
5.1 Syntactical Conventions
The Variant server manages experiment metadata in human readable YAML files, called schema files. Each schema file contains a single experiment schema describing a set of related experiments instrumented on some host application using the familiar YAML syntax.
All schema keys (nouns to the left of the :) are case-insensitive reserved keywords that have specific meanings. For example, name:, Name:, or NAME: are interchangeable.
The following conventions are used throughout this section:
any-string | Arbitrary, case sensitive, Unicode string. Follow YAML’s escape rules if you want a string contain special characters. |
name-string | Case insensitive string containing only Unicode letters, digits or the ‘_’ (underscore) and not starting with a digit. For example, _mySchema is a valid name and is the same as _MYSCHEMA, but 3rdTimesTheCharm is not a valid name. |
boolean | YAML boolean scalar value of true or false. |
number | YAML numeric scalar value. |
fragment | Arbitrary YAML fragment |
type | YAML mapping (dictionary) of some type. |
[type] | YAML sequence of mappings of a some type. |
5.2 Schema Top Level Keys
The top-level keys in the CVM grammar are:
| Key | Type | Required | Comment | Default |
|---|---|---|---|---|
name | name-string | Yes | The schema name. Must be server-wide unique. | |
description | any-string | No | Optional description. | None |
| [state] | Yes | A list of the host application’s interface states. | |
experiments | [experiment] | Yes | A list of potentially inter-dependent code experiments and gates. | |
flusher | flusher | No | Defines a schema-specific trace event flusher. Applies to all trace events generated by the experiments defined in this schema. | Server-wide default1. |
hooks | [hook] | No | A list of schema-scoped lifecycle hook specifications. Hooks defined at this scope apply to all states and all experiments defined in this schema. | [] |
1 Configured with the variant.event.fluher.* config parameters.
5.3 States
The states list contains state elements, each representing a node in the application state graph. A state element has the following keys:
| Key | Type | Required | Comment | Default |
|---|---|---|---|---|
name | name-string | Yes | This state’s name. | |
parameters | param-map | No | A map of state-scoped user-defined parameters. | {} |
hooks | [hook] | No | A list of state-scoped lifecycle hook specifications which apply only to this state. | [] |
Example:
states:
- name: state1
parameters:
key1: "a string"
key2: "a string"
- name: state2
hooks:
- class: mycompany.variant.spi.RecaptchaTargetingHookAll state-scoped hooks must listen to StateAwareLifecycleEvents.
5.4 Experiments
5.4.1 Experiment Top Level Keys
Experiments are complex structures packing most of the Variant schema’s expressive power. At a minimum, an experiment must have a name, one or more experiences, and one or more onStates elements. If there are two or more experiences, exactly one of them must be declared as control, typically representing the existing code path.
Single-experience experiments are a special case, implicitly treated as a gates, whose sole experience is always presumed to be control.
An experiment element has the following keys:
| Key | Type | Required | Comment | Default |
|---|---|---|---|---|
name | name-string | Yes | The experiment’s name. | |
experiences | [experience] | Yes | This experiment’s experiences. | |
onStates | [on-state] | Yes | The mappings of this experiment to states it instruments. | |
isOn | boolean | No | Is this experiment online? | true |
concurrentWith | [name-string] | No | A list of previously defined experiment names conjointly concurrent with this experiment. | [] |
timeToLive | time-to-live | No | Time-to-live specification | Session for both qualification and targeting. |
hooks | [hook] | No | A list of experiment-scoped lifecycle hook specifications. Hooks defined at this scope apply only to this experiment. | [] |
parameters | param-map | No | A map of experiment-scoped user-defined parameters. | {} |
For example:
experiments:
- name: myExperiment
experiences:
- name: control
isControl: true
- name: variant
onStates:
- state: state1
- state: state2
timeToLive:
targeting: experimentThe isOn property is used to turn an experiment or a gate temporarily offline without removing it from the schema. No sessions are targeted for an offline experiment, as if it didn’t exist. In fact, the only differences between an offline experiment and an experiment that is completely removed from the schema is that experiment-scoped targeting or qualification data is preserved so that, when the experiment is taken back online, return users will continue seeing the same experiences as they saw before.
All experience-scoped hooks must listen to ExperienceAwareLifecycleEvents.
5.4.2 Experiment Experiences
Each element of an experiment’s experiences list describes one of its experiences.
| Key | Type | Required | Comment | Default |
|---|---|---|---|---|
name | name-string | Yes | The experiment’s name. | |
isControl | boolean | Yes, unless this experiment has only one experience. | Defines whether this experience the control experience in this experience. | true if the only experience in this experience, false otherwise. |
parameters | param-map | No | A map of experience-scoped user-defined parameters. | {} |
5.4.3 Time-to-Live
Time-to-live determines the retention rule for qualification and targeting decisions with respect to a given experiment. The complete time-to-live specification looks as follows:
timeToLive:
qualiafication: state|session|experiment
targeting: state|session|experimentRefer to Section 2.2 Time-to-Live (TTL) for more information.
5.4.4 OnStates
The onStates key contains a list of elements, each of which describes this experiment’s instrumentation details on a particular state. Whenever an experiment instruments a state with an onStates element, this implies an obligation, on the part of the host application, to provide an implementation of a state variant for all experiences defined by the experiment, unless the key experiences explicitly excludes some of them.
An onState element can have the following keys:
| Key | Type | Required | Comment | Default |
|---|---|---|---|---|
state | name-string | Yes | The name of the state being mapped by this onStates element. | |
experiences | [name-string] | No | The list of this experiment’s experiences defined on this state. | The list of all of this experiment’s experiences. |
variants | [state-variant] | No | The list of this state’s variants. | [] |
For example, the following listing defines an experiment on two consecutive pages of a signup wizard:
states:
- name: page1
- name: page2
experiments:
- name: WizartTest
experiences:
- name: control
isControl: true
- name: variant
onStates:
- state: page1
- state: page2If the experiment is testing a new combined page that replaces the two existing pages with only one, the experiences key must be used to explicitly list those experiences that are defined:
states:
- name: page1
- name: page2
experiments:
- name: WizartTest
experiences:
- name: control
isControl: true
- name: variant
onStates:
- state: page1
- state: page2
experiences: [control] # page2 is not instrumented by variant experienceThe experiences list on line 13 implies an obligation, on the part of the host application, not to attempt to target a session for page2 if its live experience is WizardTest.variant. Doing so will result in a runtime error.
Conversely, if we wanted to test splitting an existing page1 into two new pages page1 and page2, line 13 would list the variant experience instead:
states:
- name: page1
- name: page2
experiments:
- name: WizartTest
experiences:
- name: control
isControl: true
- name: variant
onStates:
- state: page1
- state: page2
experiences: [variant] # page2 is not instrumented by control experience5.4.5 State Variants and State Parameters
For each element of the onStates list Variant schema parser implicitly creates the state variant space as a Cartesian product of the set of this experiment’s experiences and the experience sets of all experiments concurrent with this experiment, which are also defined on this state. All state variants in this variant space implicitly inherit the user-defined parameters as defined by this state or this experiment.
In most cases, this inferred state variant space is sufficient. However, in some cases, it is useful to also define state parameters at the state variant level:
# ...
onStates:
- state: state1
variants:
- experience: my_control
parameters:
path: '/path/to/something'An element of the variants key can contain the following keys:
| Key | Type | Required | Comment | Default |
|---|---|---|---|---|
experience | name-string | Yes | The name of this experiment’s experience. Cannot be the control experience | |
concurrentExperiences | [name-string] | No | The list of concurrent experiences defining this state variant. Cannot be a control experience. | []. |
parameters | {name:value,...} | No | Arbitrary properties dictionary. | {} |
If a state parameter is defined at both the base state and a state variant, the state variant value overrides the base value:
name: example
states:
- name: state1
# State parameters, specified at the state level,
# provide the base values for all variants of this state.
parameters:
key1: value1
key2: value2
experiments:
- name: experiment1
experiences:
- name: existing
isControl: true
- name: variant
onStates:
- state: state1
variants:
- experience: variant
# State parameters, specified at the state variant level,
# at runtime override the likely-keyed base values within
# the scope of the enclosing state variant.
parameters:
key2: 'value2 in state variant'
key3: 'value3 in state variant'At runtime, Variant will return the following values to the host application:
stateRequest.getResolvedStateParameters().get("key1"); // "value1"
stateRequest.getResolvedStateParameters().get("key2"); // "value2 in state variant"
stateRequest.getResolvedStateParameters().get("key3"); // "value3 in state variant"This mechanism of state parameter overrides is a convenient way for the developer to introduce application state into the schema at both global and local scopes.
5.5. Flusher
The schema flusher key can contain the following keys:
| Key | Type | Required | Comment | Default |
|---|---|---|---|---|
class | any-string | Yes | The fully qualified name of the Java class implementing the flusher. | |
name | name-string | No | This hook’s name. | The simple (unqualified) class name. |
init | fragment | No | Any YAML value. | None |
Example:
name: my_schema
flusher:
- class: mycompany.variant.spi.CustomFlusher
init:
endpoints: [http:/some.url http:/some.other.url]In this example, CustomFlusher‘s constructor will know what to do with the two URLs supplied in the init key. Refer to the Variant Experiment Extension SPI User Guide for more information.
5.6 Common Schema Components
5.6.1 User-Defined Parameters
User-defined parameters (UDPs) help host applications enrich experiment schema with application-specific state. They are simple read-only key/value pairs of strings, whose semantics are entirely up to the host application.
UDPs can be attached to a state or to an experiment:
name: example
states:
- name: state1
parameters:
key1: 'state param 1 in state1'
key2: 'state param 2 in state1'
experiments:
- name: experiment1
experiences:
- name: new_feature
parameters:
key1: 'experiment param 1 in experiment1'
key2: 'experiment param 1 in experiment1'
onStates:
- state: state1State-scoped UDPs can be further specified at the state variant level:
name: example
states:
- name: state1
parameters:
key1: 'state param 1 in state1'
key2: 'state param 2 in state1'
experiments:
- name: experiment1
experiences:
- name: exp1
onStates:
- state: state1
variants:
- experience: new_feature
parameters:
key1: 'overrides value of key1 in state1 and live experice exp1'
key3: 'adds a new parameter in state1 and live experience exp1'Likewise, experiment-scoped UDPs can be further specified at the experience level:
name: example
states:
- name: state1
experiments:
- name: experiment1
parameters:
key1: 'experiment param 1 in experiment1'
key2: 'experiment param 2 in experiment1'
experiences:
- name: A
isControl: true
- name: B
parameters:
key1: 'overrides value of key1 in experience B'
key3: 'adds a new parameter only to experience B'
onStates:
- state: state1At runtime, the values of user defined parameters can be retrieved via the client SDKs:
State.getParameters() | Retrieves those parameters defined with the state. |
StateRequest.getStateParameters() | Retrieves those parameters defined both with the state and with the state variant to which this state request was targeted. In case of key collisions, the state variant scoped value overrides the state scoped value. |
Experiment.getParameters() | Retrieves those parameters defined with the experiment. |
Experience.getParameters() | Retrieves those parameters defined both with the experiment and with this experience. In case of key collisions, the experience scoped value overrides the experiment scoped value. |
User defined parameters cannot be updated by the host application.
5.6.2 Lifecycle Event Hooks
The schema definition of a hook in any scope has the following three components
| Key | Type | Required | Comment | Default |
|---|---|---|---|---|
class | any-string | Yes | The fully qualified name of the Java class implementing the hook. | |
name | name-string | No | This hook’s name. | The simple (unqualified) class name. |
init | fragment | No | Any YAML value. | None |
Example:
name: minimal_schema
...
hooks:
- class: mycompany.variant.spi.RecaptchaQualificationHook
init: [USERID1 USERID2 USERID3]In this example, RecaptchaQualificationHook‘s constructor will know what to do with the three user IDs supplied in the init key. Refer to the Variant Experiment Server Extension SPI User Guide for more information.
6 Variant Runtime
6.1 The Lifecycle of a State Request
Variant treats interactive applications as finite state machines. Each user session traverses some state graph, whose nodes are interface states. In these states the host application pauses for user input. Whenever a user navigates to the next application state, the host application must determine if this state exists in more than one variant (i.e. if it is instrumented by any experiments), and, if so, determine which of these variants to return. This derivation is known as targeting of a session for a state.
The host application delegates session targeting to Variant server by calling the Session.targetForState(state) client API method. It returns the StateRequest object which can be further examined for the list of live experiences in all experiments instrumented on this state. Before any targeting can happen, the session must be created first with the Connection.getOrCreateSession() method.
See Variant Java Client for more details.
A Variant session can be thought of as a succession of consecutive state requests, each advancing it from one interface state to the next. Variant sessions provide
- A way to identify a user across multiple state requests;
- Storage for the session state that must be preserved between state requests;
- Metadata isolation context.
Variant server acts as the centralized session repository, accessible to any Variant client by the session ID. Host application can add session attributers which are preserved between state requests. Sessions are automatically expired by Variant after a configurable period of inactivity.
Variant isolates in-progress sessions from changes to experiment schema. Whenever experiment schema is updated, active sessions continue to see the old generation of the schema, as it existed at the time when the sessions were created. This isolation guarantee is critical in protecting user sessions from (potentially fatal) inconsistencies.
Note, that Variant sessions are completely separate of the host application’s own native sessions. Variant sessions are configured independently and do not require that the host application even have any native notion of a session.
Much of the complexity hidden by Variant server from the application developer resides inside the Session.targetForState(state) method. For each experiment instrumented on the given state, Variant server must perform the following steps:

Figure 7. Qualification and targeting of a session.
The Session.targetForState(state) method returns a StateRequest which contains all the targeting information that a host application requires to make the determination which code path to take. Once the host application has completed the state transition and is about to target the session for the next interface state, it must complete the current state request by calling either commit() (if all went according to plan) or fail() (if an exception was encountered). This completes the state request and triggers the implicit state visited trace event. The downstream data science pipeline will be able to easily determine which state transitions encountered exception and should be excluded from statistical analysis.
6.2 Session Qualification and Targeting
Whenever, a host application calls Session.targetForState(State) API method, Variant server must consider many different factors in order to determine the session’s participation details in all experiments instrumented on the requested state. Even in a serial case, when the requested state is only instrumented by one experiment, the qualification and targeting details may be complex:
- Are all experiences defined on this state?
- Are there other experiments that, although not defined on this state, are concurrent with this experiment?
- Are there explicit consonance rules that must be obeyed?
The complexity of the targeting algorithm grows dramatically when the requested state is instrumented by multiple experiments. Variant handles all this complexity, relieving the application programmer from the onus of coding for it. However, there are certain details that the application programmer should keep in mind.
Variant server considers pre-existing qualification and targeting information, as defined by the time-to-live settings. Whenever Variant determines that the user session’s qualification for a particular experiment must be (re)established, it raises the QualificationLifecycleEvent, which posts all eligible custom lifecycle hooks. If none were defined in the schema, or none returned a result, the default built-in qualification hook is posted, which always returns an answer.
When Variant disqualifies a session from participation in an experiment the StateRequest object, returned by Session.targetForState(), will contain no entry for this experiment. The host application should interpret that somewhat differently depending on whether the experiment is in fact an experiment (has at least one non-control experience) or a gate (has a sole control experience). In the case of an experiment, the host application should take the control code path. In the case of a gate, the host application should consider the gate closed.
When Variant qualifies a session for an experiment, it proceeds to the targeting step. Again, Variant server will consider pre-existing targeting information first, subject to as defined by the time-to-live settings. Whenever Variant determines that the user session must be (re)targeted for a particular experiment, it raises the TargetingLifecycleEvent, which posts all eligible custom lifecycle hooks. If none were defined in the schema, or none returned a result, the default built-in targeting hook is posted, which always returns an answer.
For more information, see Variant Experiment Server Extension SPI User Guide.
6.3 Schema Management
When Variant server starts, it looks for experiment schema files in the schemata directory and attempts to deploy them. A schema file must contain exactly one uniquely named Variant schema. There is no requirement that the name of the schema file match that of the schema contained therein, though it is a good idea.
For each schema file in the schemata directory Variant server takes these steps:
- Parse. Any messages emitted by the parser are written to the server log file. If any parser errors were encountered, Variant server moves to the next schema file.
- If no errors, Variant deploys this schema and moves to the next schema file.
In order to make any changes to the schema, the file which contains it must be replaced in the schemata directory with one containing the new version of the schema. The change will be detected and Variant server will attempt to re-deploy the schema by following these steps:
- Parse. Any messages emitted by the parser are written to the server log file. If any parser errors were encountered, Variant server keeps the existing schema.
- If no errors, Variant checks for these two additional conditions:
- If no currently deployed schemata has the same name as this schema, this schema is deployed.
- If a currently deployed schema has the same name as this schema, their respective file names must also be the same. (In particular, this means that a schema file can be edited in place, so long as the name of the schema it contains does not change.) If this condition holds, Variant deploys the new generation of this schema, while keeping the previous generation around for as long as it is required by any user sessions that were created when the previous generation was current. Once all such sessions drain naturally, Variant server vacuums it.
Variant schema is undeployed when
- Its schema file is deleted. When this happens, Variant stops accepting new session creation requests from the clients against this schema, but keeps the current generation around for as long as it is required by any user sessions that were created when the schema was active. Once all such sessions drain naturally, Variant server completely removes and vacuums the schema.
- Its schema file is replaced with the next generation the currently deployed schema. When this happens, Variant creates new sessions agains the new generation, but keeps the previous generation(s) of the schema around for as long as it is required by any user sessions that were created when the previous generation(s) were active. Once all such sessions expire naturally, Variant server removes the previous generation(s) of the schema.
- Variant server is shutdown with
variant stopor^C(graceful shutdown). In response, Variant stops accepting all new session creation requests from the clients, but keeps the current generations of all schemas around for as long as it is required by any active user sessions. Once all such sessions expire naturally, Variant server shuts down and the commandvariant stopreturns. - Variant server shutdown with
variant halt(emergency shutdown). Variant stops accepting all new sessions creation requests and undeploys all schemas immediately, without waiting for active sessions to drain.
Session draining isolates active sessions from schema updates, which is instrumental in Variant’s ability to provide stable qualification and targeting.
6.4 Trace Event Logging
Variant trace events are generated as user traffic flows through instrumented code paths with the purpose of subsequent analysis by a downstream process. Trace events can be triggered implicitly, by Variant, or explicitly by the host application. In either case, the host application can enrich them with custom attributes, which will help in the analysis.
The only implicit trace event is the state visited event (SVE). It is created by Session.targetForState(), whenever the resulting StateRequest has at least one live experience. At this point the host application can attach custom attributes to the event. The SVE is committed and passed to the trace event flusher when either StateRequest.commit() or StateRequest.fail() is called.
The host application can trigger custom trace events explicitly by calling Session.triggerTraceEvent(TraceEvent) and passing it an implementation of TraceEvent.