

Experiment Lifecycle
By Igor Urisman, August 17, 2024.
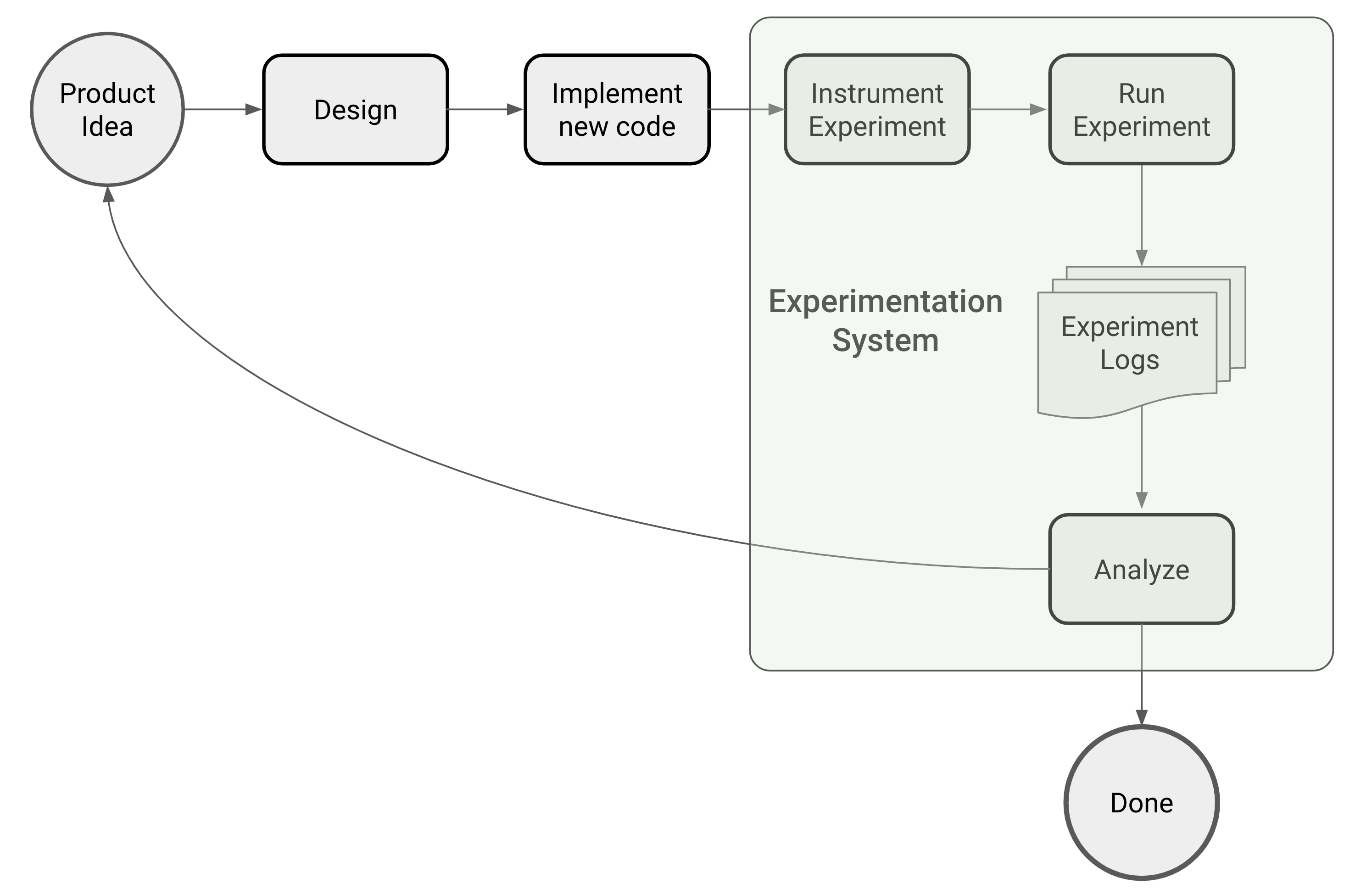
1. The Six Stages of and Online Controlled Experiment
Every experiment has a clearly defined lifespan. It starts out as an idea for a new product feature or an improvement to an existing one and ends with the conclusion whether or not to open it to a wider audience.
Let’s consider each of the lifecycle states with a concrete example. Suppose you have a signup funnel where your visitors signup for your service.
1.1. Product Idea
Someone in product comes up with the idea that the 2-page signup wizard is too cumbersome and proposes to combine the two pages into one, while deferring some of the items until after signup.
1.2. Experiment Design
This is where the nebulous references to something being better are translated into a metric that can be measured and analyzed. In this case, the target metric may be as simple as the conversion rate as measured by the number of people who signed up. However, a more experienced experiment designer will likely look for a metric with a longer time horizon, particularly if some of the key answers are deferred until after the signup.
Another part of the experiment design is figuring out how it should interact with existing features and—crucially—with other experiments. For example, you may want to exclude from the experiment those users who come to your site in response to a promotion.
1.3. Implement New Code Path
The home cook’s motto, “The only way to taste it is to make it,” applies perfectly to controlled online experiments. If you wish to validate a new product idea empirically you must code it up first. The outcome of the experiment will tell you whether it’s worth deploying.
1.4. Instrument New Code Path as Experiment
Instrumentation adds to the host application’s codebase the logic to generate logs to be analyzed by a downstream analytical component, as described in section 6 below. This code is a throwaway, because it will be unneeded and should be discarded after the experiment concludes.
At the same time, the instrumentation code is often more complex than the implementation code because the instrumentation code has to provide certain guarantees if the resulting logs are to be trustworthy. See The Three Tenets of Experimentation System Design for details on these guarantees.
1.5. Run Experiment
A running experiment produces logs which are analyzed by a downstream analytical component. These logs contain the target metric values for each user session along with additional information that may be required for the analysis.
1.6. Analyze Experiment
The goal of this component is to use statistical inference to support the claim that the observed difference in the target metrics between control and treatment experience(s) can be interpreted as being caused by the treatment. There’s an abundance of literature on the various methods of statistical inference that are commonly used. For a good recent survey, see Quin et al.
Statistical analysis may produce two outcomes:
Success is when the computed probability of the observed difference being due to mere chance is low enough that we are confident to assume that the only other explanation—that this difference is due to the difference in treatment—is accepted. In this case the experiment is concluded with:
- The control code path is replaced with the winning variant code path;
- The instrumentation code is discarded.
Failure is the exact opposite, when the computed probability of the observed difference being due to mere chance is not low enough to give us the confidence to reject it. In this case you have the choice between rethinking your feature idea and re-implementing it, or concluding the experiment with:
- The variant code path(s) are discarded;
- The instrumentation code is discarded.
2. Instrumentation and Analysis Have Different Complexity
It should be clear by now that any experimentation system has to provide two disparate capabilities: instrumentation and analysis. While discussions of the statistical analysis dominate the social media and the literature, the instrumentation is commonly if unwittingly thought of as an afterthought easily attainable by a rank-and-file developer. Nothing could be farther from the truth.
The way to understand the difference is to think of your experimentation practice in terms of complexity as a function of the number of concurrent experiments you run. In the simplest case, if you only run one experiment, the instrumentation is straightforward because you don’t worry about any interference from other experiments in targeting your users. You may still have to worry about such things as qualification, e.g. when users come from channels you don’t wish to include in the experiment, but that’s typically straightforward as well, with only one experiment to worry about.
At this low end of experiment concurrency, the cost of statistical analysis dominates the overall complexity because the algorithms are complex and often poorly understood. However, once the tooling for analysis is in place, analyzing additional experiments (concurrent or not) is just a matter of running more data through it — a manageable linear complexity O(n).
On the other hand, the complexity of instrumentation grows quadratically, i.e. O(n2) because in the general case you must consider the interplay between all concurrent experiments. The number of such pairwise relationships is equal to the number of edges in a complete undirected graph n(n-1)/2.
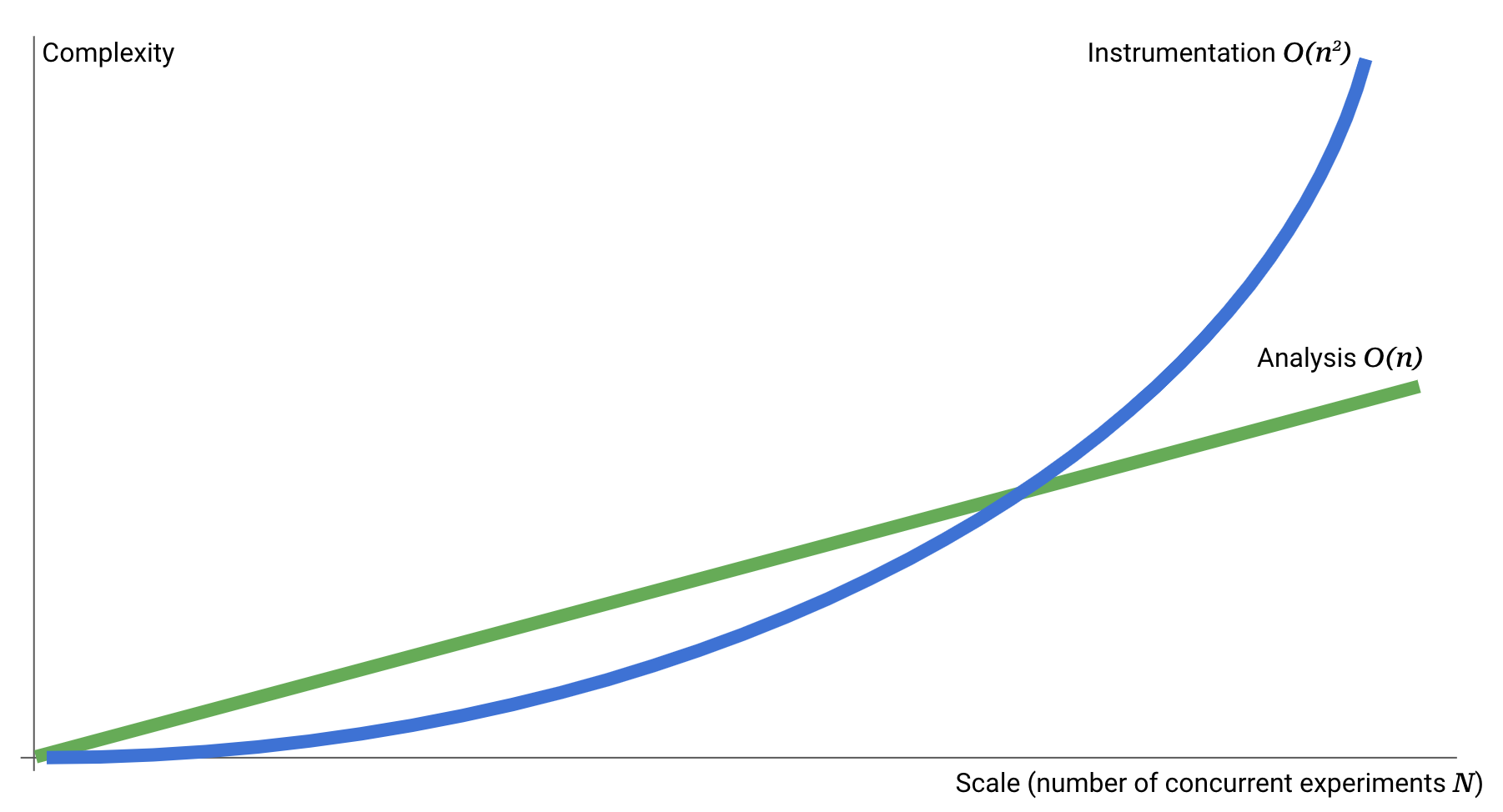
This complexity mismatch is a hard problem to solve because
- It crops up after a team has committed to developing its own experimentation framework. What seemed straightforward turns out hard or even undoable after considerable effort has already been invested.
- There is no literature or thought leadership on how to address instrumentation, apart from the general programming principles.
3. Variant’s Instrumentation-First Attitude
Variant is the only technology on the market that addresses this imbalance. It uses a sophisticated domain model and a rich grammar informed by it, which allows you to imbue Variant server with complete understanding of all experiments on your host application and their interplay. This knowledge enables Variant server to do all the hard work of figuring out your users’ qualification and targeting without a single line of code in the host application.
The gold standard of an experimentation system is to be able answer the key question: what are the live experiences that must be honored for a given user session in a given application state. To illustrate this with a practical example, suppose that in addition to the signup funnel consolidation experiment, you’re running another experiment in which you test new field names on both existing pages. Furthermore, in order not to waste traffic you’ve implemented the hybrid variant (in which the consolidated page also has the new field names) which allows you to run the two experiments concurrently. Below is the schema for these two experiments:
states:
- name: funnelPage1
- name: funnelPage2
experiments:
- name: funnelConsolidation # Consolidate 2 existing pages into one
experiences:
- name: existing # Two-page funnel
isControl: true
- name: consolidated # Single-page consolidated funnel
onStates:
- name: funnelPage2
experiences: [existing] # Consolidated variant does not have page 2
- name: funnelFieldNames # Change names of some of the fields.
experiences:
- name: existing # The existing codepath
isControl: true
- name: newNames # Fields have new names.
concurrentWith: [funnelConsolidation] When the host application is about to show the first page of the funnel, it makes a single call to the Variant server to get the list of its live experiences.
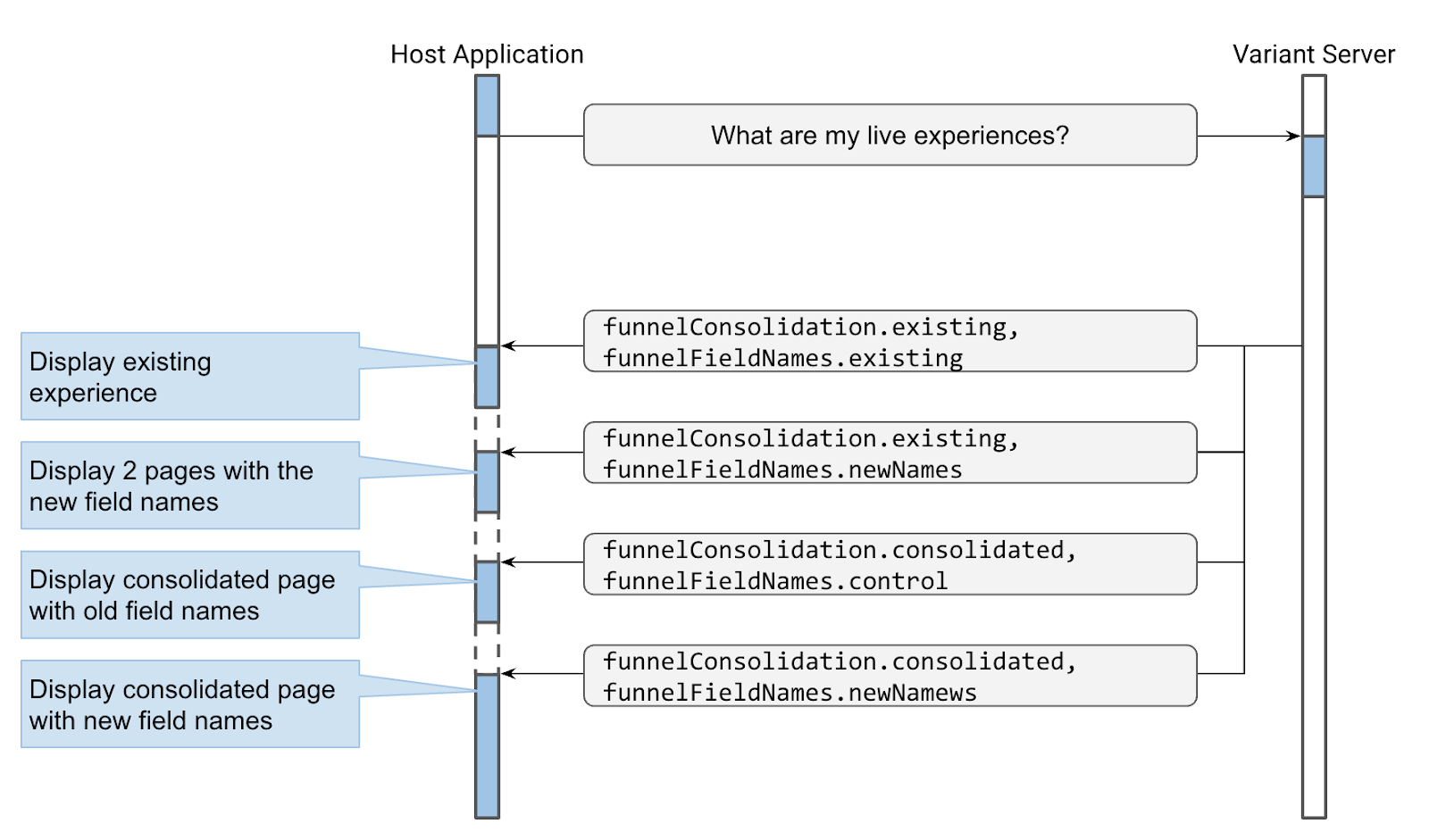
This example clearly illustrates Variant’s power of enabling a complete separation of implementation from instrumentation. The host application does not worry about the details of how its code paths are instrumented as experiments. It simply asks Variant server what code path to execute. All the complexity of generating that answer is handled by the Variant server without any application code. Even with two concurrent experiments this seems a clear win. Enterprises run tens or even hundreds of concurrent experiments at the exorbitant cost of polluting the application code base with brittle and smelly instrumentation code.